
 Doriand Petit
před 4 roky
Doriand Petit
před 4 roky
35 změnil soubory, kde provedl 1399 přidání a 6806 odebrání
binární
code/wilshire_5000/0.00890727061778307_100epochs_snake.png
Zobrazit soubor
{kind=link}
binární
code/wilshire_5000/100epochs_2runs_4batchsize.png
Zobrazit soubor
{kind=link}
binární
code/wilshire_5000/30aplot1.png
Zobrazit soubor
{kind=link}
binární
code/wilshire_5000/30aplot2.png
Zobrazit soubor
{kind=link}
+ 7
- 0
code/wilshire_5000/Snake100a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake100a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake100a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake100a/variables/variables.index
Zobrazit soubor
+ 7
- 0
code/wilshire_5000/Snake10a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake10a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake10a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake10a/variables/variables.index
Zobrazit soubor
+ 7
- 0
code/wilshire_5000/Snake1a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake1a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake1a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake1a/variables/variables.index
Zobrazit soubor
+ 7
- 0
code/wilshire_5000/Snake20a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake20a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake20a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake20a/variables/variables.index
Zobrazit soubor
+ 7
- 0
code/wilshire_5000/Snake30a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake30a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake30a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake30a/variables/variables.index
Zobrazit soubor
+ 7
- 0
code/wilshire_5000/Snake50a/keras_metadata.pb
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/Snake50a/saved_model.pb
Zobrazit soubor
binární
code/wilshire_5000/Snake50a/variables/variables.data-00000-of-00001
Zobrazit soubor
binární
code/wilshire_5000/Snake50a/variables/variables.index
Zobrazit soubor
+ 1305
- 1
code/wilshire_5000/WILL5000INDFC.csv
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
+ 0
- 6785
code/wilshire_5000/WILL5000INDFC2.csv
Diff nebyl zobrazen, protože je příliš veliký
Zobrazit soubor
binární
code/wilshire_5000/a_plot.png
Zobrazit soubor
{kind=link}
binární
code/wilshire_5000/new_bs1_20ep_30a_001lr.png
Zobrazit soubor
{kind=link}
binární
code/wilshire_5000/new_bs1_20ep_50a_001lr.png
Zobrazit soubor
{kind=link}
+ 52
- 14
code/wilshire_5000/nn.py
Zobrazit soubor
| from statsmodels.tsa.arima.model import ARIMA | from statsmodels.tsa.arima.model import ARIMA | ||||
| def snake(x): | def snake(x): | ||||
| return(x+(tf.math.sin(50*x)**2)/50) | |||||
| return(x+(tf.math.sin(20*x)**2)/20) | |||||
| def sinus(x): | def sinus(x): | ||||
| return(tf.math.sin(x)) | return(tf.math.sin(x)) | ||||
| def sinus_cosinus(x): | def sinus_cosinus(x): | ||||
| activations = [snake] | activations = [snake] | ||||
| def prepare_data(filename="WILL5000INDFC2.csv"): | |||||
| def prepare_data(filename="WILL5000INDFC.csv"): | |||||
| df_train,df_test,index = wilshire.preprocess(filename) | df_train,df_test,index = wilshire.preprocess(filename) | ||||
| x_train = np.arange(df_train.shape[0]) | x_train = np.arange(df_train.shape[0]) | ||||
| maximum = np.max(x_train) | maximum = np.max(x_train) | ||||
| def arima_pred(y_train,y_test,orders=[[2,1,1],[2,2,1],[3,1,1],[2,1,2]],n=5): | def arima_pred(y_train,y_test,orders=[[2,1,1],[2,2,1],[3,1,1],[2,1,2]],n=5): | ||||
| mse=[] | mse=[] | ||||
| for order in orders : | for order in orders : | ||||
| mean_err=np.array() | |||||
| mean_err= [] | |||||
| for k in range(n): | for k in range(n): | ||||
| train = y_train | train = y_train | ||||
| preds = [] | preds = [] | ||||
| model = ARIMA(train, order=(order[0],order[1],order[2])) | model = ARIMA(train, order=(order[0],order[1],order[2])) | ||||
| model = model.fit() | model = model.fit() | ||||
| output = model.forecast() | output = model.forecast() | ||||
| preds.append(output[0]) | |||||
| #print(output) | |||||
| preds.append(output) | |||||
| #train.append(y_test[te | #train.append(y_test[te | ||||
| mean_err.append((np.square(np.array(preds) - np.array(y_test))).mean()) | mean_err.append((np.square(np.array(preds) - np.array(y_test))).mean()) | ||||
| mse.append(mean_err.mean()) | |||||
| mse.append([np.array(mean_err).mean(),np.array(mean_err).std()]) | |||||
| return(mse) | return(mse) | ||||
| model.add(tf.keras.layers.Dense(64,activation=activation)) | model.add(tf.keras.layers.Dense(64,activation=activation)) | ||||
| model.add(tf.keras.layers.Dense(1)) | model.add(tf.keras.layers.Dense(1)) | ||||
| opt = tf.keras.optimizers.SGD(learning_rate=0.01,momentum=0.9) | |||||
| opt = tf.keras.optimizers.SGD(learning_rate=0.01,momentum=0.8) | |||||
| model.compile(optimizer=opt, loss='mse') | model.compile(optimizer=opt, loss='mse') | ||||
| model.build() | model.build() | ||||
| model.summary() | model.summary() | ||||
| errors_test_5=[] | errors_test_5=[] | ||||
| for k in range(n): | for k in range(n): | ||||
| model = create_model(activations) | |||||
| model.fit(x_train,y_train, batch_size=1, epochs=1) | |||||
| model = create_model(activation) | |||||
| model.fit(x_train,y_train, batch_size=1, epochs=50) | |||||
| y_pred_test = model.predict(x_test) | y_pred_test = model.predict(x_test) | ||||
| y_pred_train = model.predict(x_train) | y_pred_train = model.predict(x_train) | ||||
| errors_test.append([np.mean(errors_test_5),np.std(errors_test_5)]) | errors_test.append([np.mean(errors_test_5),np.std(errors_test_5)]) | ||||
| # y_preds_train.append(y_pred_train) | # y_preds_train.append(y_pred_train) | ||||
| # y_preds_test.append(y_pred_test) | # y_preds_test.append(y_pred_test) | ||||
| return models,errors_train,errors_test | |||||
| return models,errors_train,errors_test | |||||
| def final_plot(models,errors_test,arima_err): | |||||
| def final_plot(models,errors_test,arima_err,activations=["ReLU","Swish","Sinus Cosinus","Sinus","Snake"]): | |||||
| x_train,x_test,y_train,y_test,maximum,index = prepare_data(filename="WILL5000INDFC2.csv") | x_train,x_test,y_train,y_test,maximum,index = prepare_data(filename="WILL5000INDFC2.csv") | ||||
| x = np.arange(9000) | x = np.arange(9000) | ||||
| x_n = x / maximum | x_n = x / maximum | ||||
| print("----- ARIMA Test MSE -----") | print("----- ARIMA Test MSE -----") | ||||
| orders_ARIMA = ["[2,1,1]","[2,2,1]","[3,1,1]","[2,1,2]"] | orders_ARIMA = ["[2,1,1]","[2,2,1]","[3,1,1]","[2,1,2]"] | ||||
| for k in range(len(orders_ARIMA)): | |||||
| print("ARIMA"+orders_ARIMA[k]+" : "+str(arima_err[k])) | |||||
| # for k in range(len(orders_ARIMA)): | |||||
| # print("ARIMA"+orders_ARIMA[k]+" : "+str(arima_err[k])) | |||||
| print("----- DNN Test MSE -----") | print("----- DNN Test MSE -----") | ||||
| activations = ["ReLU","Swish","Sinus Cosinus","Sinus","Snake"] | |||||
| for k in range(len(activations)): | for k in range(len(activations)): | ||||
| print("DNN "+activations[k]+" : "+str(errors_test[k])) | print("DNN "+activations[k]+" : "+str(errors_test[k])) | ||||
| plt.figure() | plt.figure() | ||||
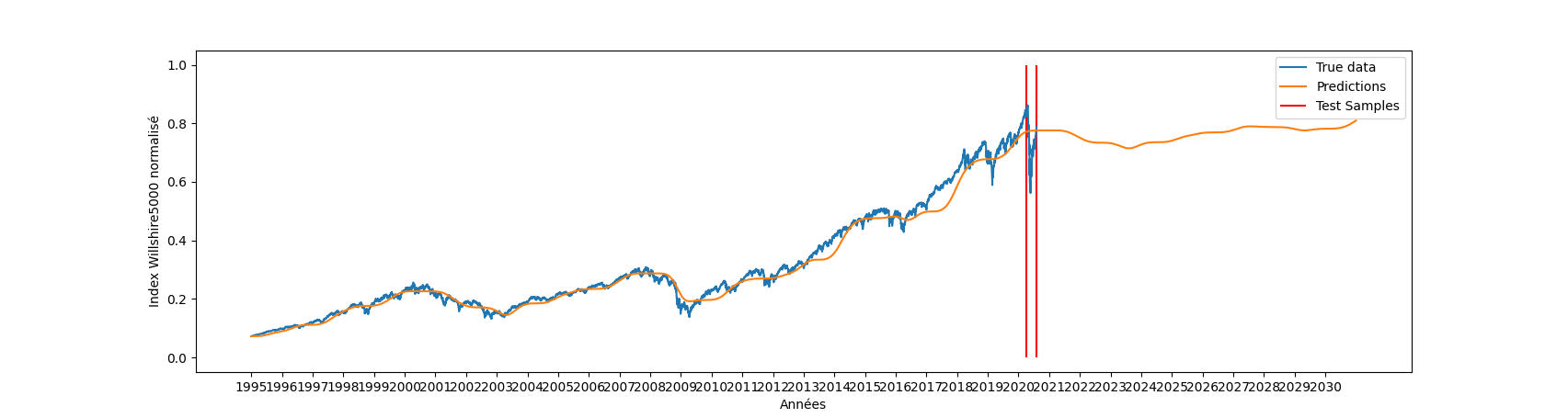
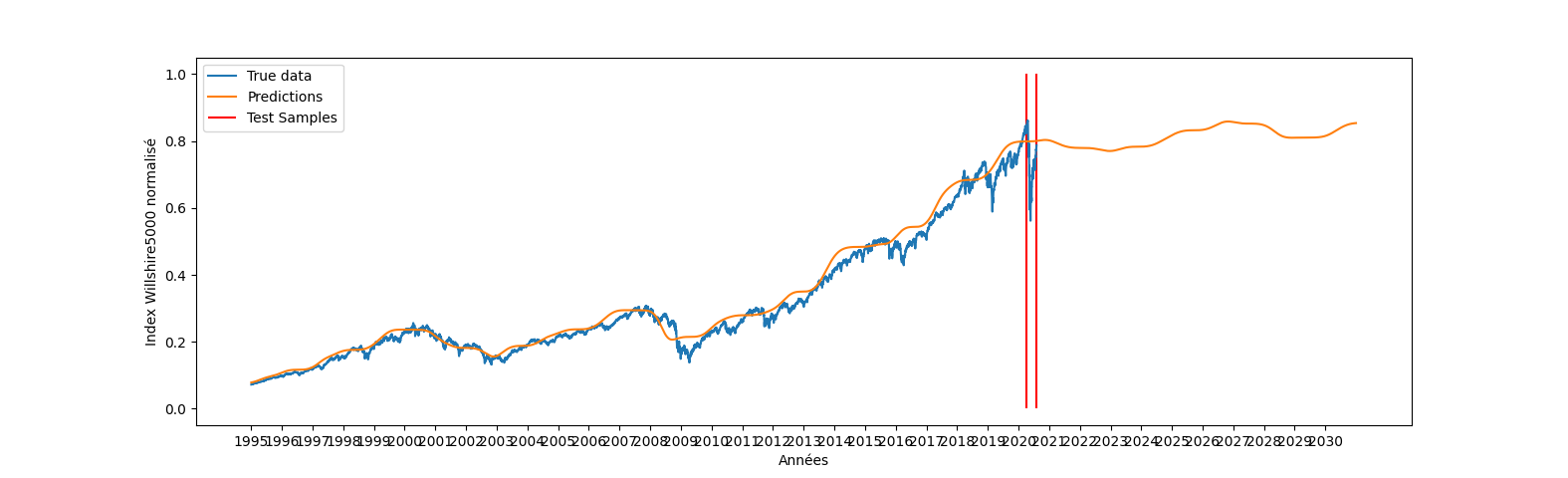
| plt.plot(x_cut,y_true,label="True data") | plt.plot(x_cut,y_true,label="True data") | ||||
| plt.plot(x,future_preds,label="Predictions") | plt.plot(x,future_preds,label="Predictions") | ||||
| plt.xticks(range(0, 9000, 250), range(1995, 2031, 1)) | |||||
| plt.xticks(range(0, 9000, 500), range(1995, 2031, 2)) | |||||
| plt.xlabel("Années") | plt.xlabel("Années") | ||||
| plt.ylabel("Index Willshire5000 normalisé") | plt.ylabel("Index Willshire5000 normalisé") | ||||
| plt.vlines([index,index+85],ymin=0,ymax=1,colors="r",label="Test Samples") | plt.vlines([index,index+85],ymin=0,ymax=1,colors="r",label="Test Samples") | ||||
| plt.show() | plt.show() | ||||
| x_train,x_test,y_train,y_test,maximum,index = prepare_data() | |||||
| #mse = arima_pred(y_train,y_test) | |||||
| # mse=[] | |||||
| # # models,errors_train,errors_test = training_testing(n=1,activations=[snake]) | |||||
| # # models[0].save("Snake20a") | |||||
| # models=[] | |||||
| # errors_test=[] | |||||
| # models.append(tf.keras.models.load_model("Snake30a")) | |||||
| # print(mse,errors_test) | |||||
| # final_plot(models,errors_test,mse,activations=[]) | |||||
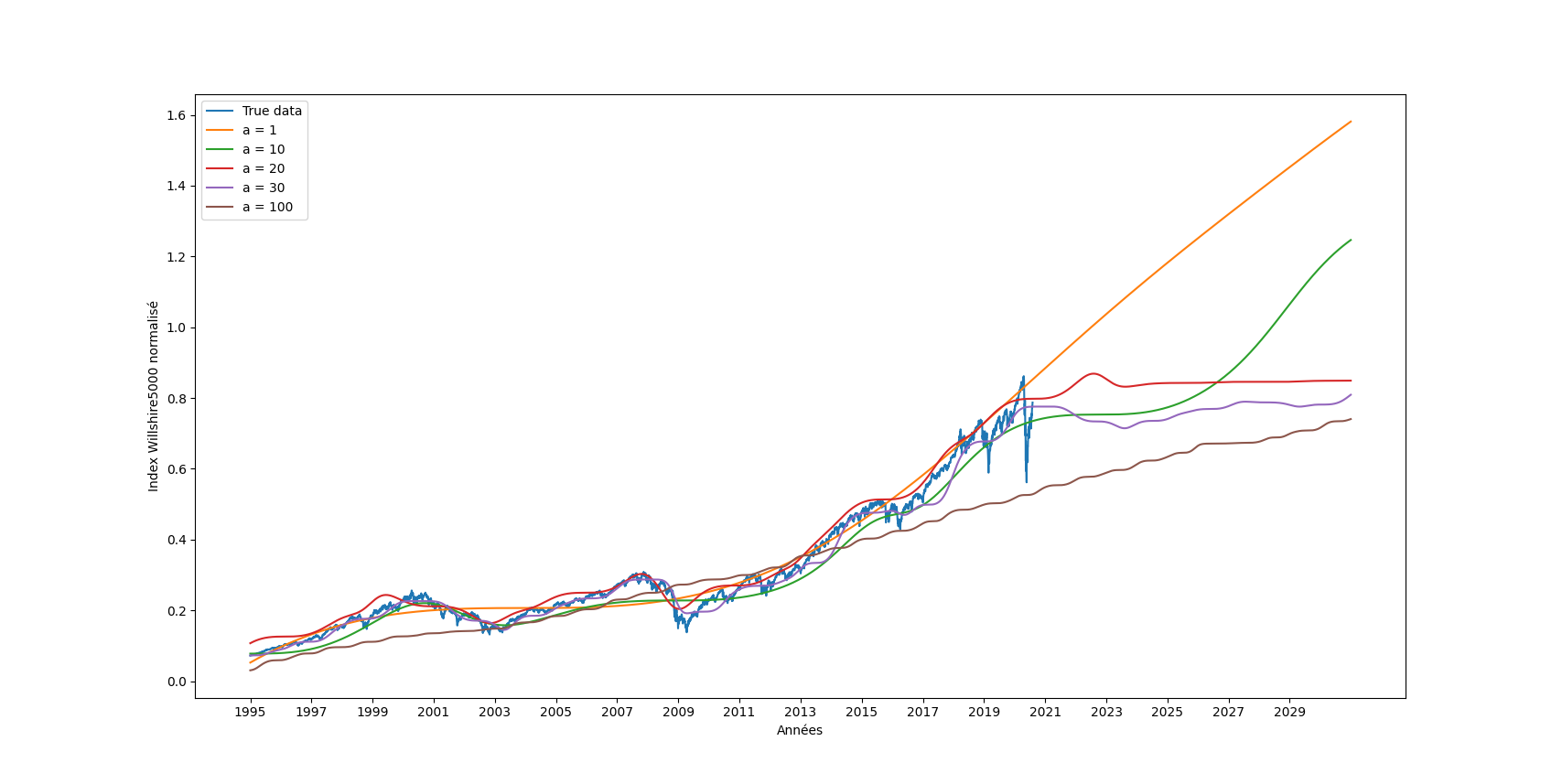
| def plot_all_a(a=["1","10","20","30","100"]): | |||||
| models=[] | |||||
| for param in a : | |||||
| models.append(tf.keras.models.load_model("Snake"+param+"a")) | |||||
| x_train,x_test,y_train,y_test,maximum,index = prepare_data(filename="WILL5000INDFC2.csv") | |||||
| x = np.arange(9000) | |||||
| x_n = x / maximum | |||||
| y_true = np.concatenate((y_train,y_test)) | |||||
| x_cut = np.arange(x_train.shape[0]+x_test.shape[0]) | |||||
| future_preds=[] | |||||
| for k in range(len(models)): | |||||
| future_preds.append(models[k].predict(x_n) ) | |||||
| plt.figure() | |||||
| plt.plot(x_cut,y_true,label="True data") | |||||
| for k in range(len(models)): | |||||
| plt.plot(x,future_preds[k],label="a = "+a[k]) | |||||
| plt.xticks(range(0, 9000, 500), range(1995, 2031, 2)) | |||||
| plt.xlabel("Années") | |||||
| plt.ylabel("Index Willshire5000 normalisé") | |||||
| plt.legend() | |||||
| plt.show() | |||||
| # plot_all_a() |
+ 0
- 6
code/wilshire_5000/wilshire.py
Zobrazit soubor
| def parser(path): | def parser(path): | ||||
| df = pd.read_csv(path,na_values='.') | df = pd.read_csv(path,na_values='.') | ||||
| print(df.shape) | |||||
| #df = df.interpolate() | #df = df.interpolate() | ||||
| df = df.dropna().reset_index(drop=True) | df = df.dropna().reset_index(drop=True) | ||||
| print(df.shape) | |||||
| #df = df.drop(labels=np.arange(1825)) ### To obtain the same graph than in the article | #df = df.drop(labels=np.arange(1825)) ### To obtain the same graph than in the article | ||||
| print(df.shape) | |||||
| return(df) | return(df) | ||||
| def preprocess(path): | def preprocess(path): | ||||
| df_normalized = df[:] | df_normalized = df[:] | ||||
| df_normalized["WILL5000INDFC"]=df_normalized["WILL5000INDFC"]/np.max(df_normalized["WILL5000INDFC"]) | df_normalized["WILL5000INDFC"]=df_normalized["WILL5000INDFC"]/np.max(df_normalized["WILL5000INDFC"]) | ||||
| index_train = int(df_normalized[df_normalized["DATE"]=="2020-01-31"].index.array[0]) | index_train = int(df_normalized[df_normalized["DATE"]=="2020-01-31"].index.array[0]) | ||||
| print(df) | |||||
| print(df_normalized) | |||||
| print(df_normalized[df_normalized["DATE"]=="2020-01-31"]) | |||||
| # df.plot() | # df.plot() | ||||
| # plt.show() | # plt.show() | ||||
| df_train = df_normalized[:index_train] | df_train = df_normalized[:index_train] |
Načítá se…