

41 zmienionych plików z 3523 dodań i 71 usunięć
BIN
code/RNN_wilshire_5000/images/140_84_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/140_84_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/140_84_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/149_117_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/149_117_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/149_117_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/165_119_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/165_119_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/165_119_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/197_45_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/197_45_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/197_45_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/204_254_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/204_254_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/204_254_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/211_133_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/211_133_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/211_133_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/234_67_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/234_67_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/234_67_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/238_208_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/238_208_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/238_208_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/256_32_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/256_32_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/256_32_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/70_234_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/70_234_fig3.png
Wyświetl plik
{kind=link}
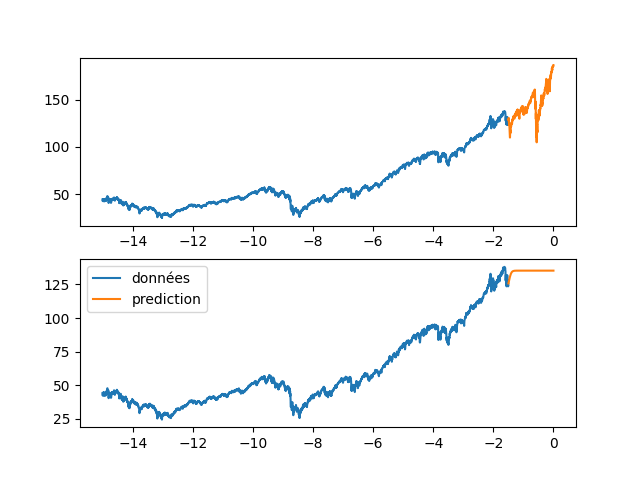
BIN
code/RNN_wilshire_5000/images/70_234_fig4.png
Wyświetl plik
{kind=link}
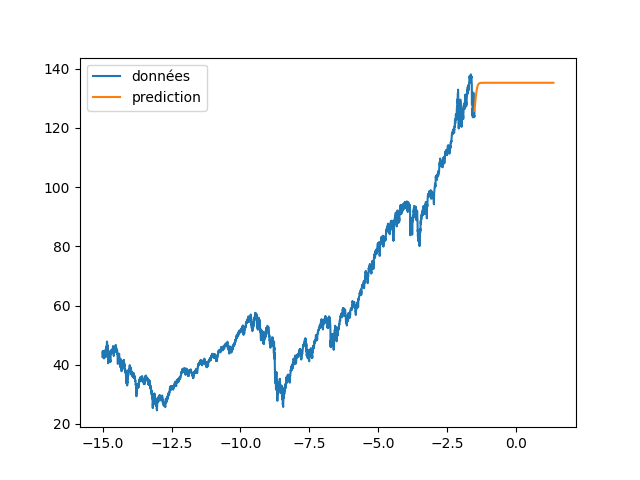
BIN
code/RNN_wilshire_5000/images/89_85_fig2.png
Wyświetl plik
{kind=link}
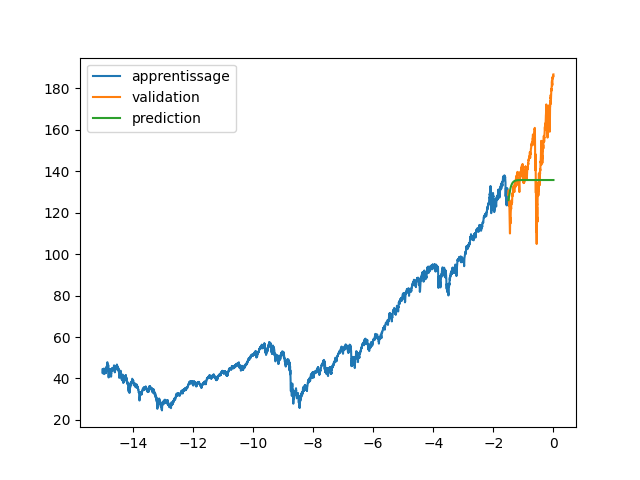
BIN
code/RNN_wilshire_5000/images/89_85_fig3.png
Wyświetl plik
{kind=link}
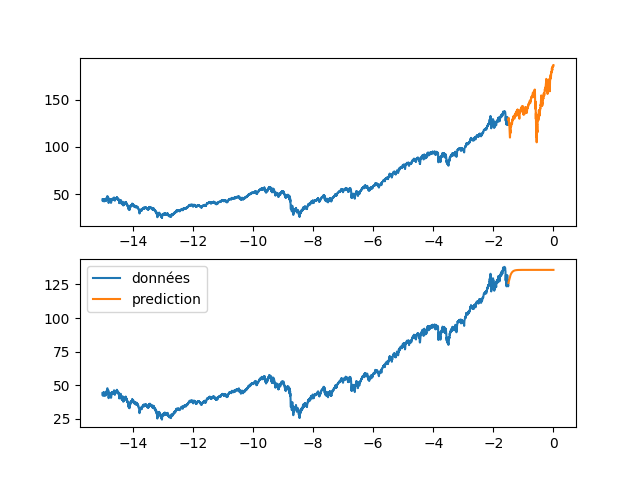
BIN
code/RNN_wilshire_5000/images/89_85_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/97_196_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/97_196_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/97_196_fig4.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/98_115_fig2.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/98_115_fig3.png
Wyświetl plik
{kind=link}
BIN
code/RNN_wilshire_5000/images/98_115_fig4.png
Wyświetl plik
{kind=link}
+ 3430
- 0
code/RNN_wilshire_5000/rep.txt
Plik diff jest za duży
Wyświetl plik
+ 93
- 71
code/RNN_wilshire_5000/training.py
Wyświetl plik
| @@ -2,74 +2,96 @@ import tensorflow as tf | |||
| from matplotlib import pyplot as plt | |||
| import numpy as np | |||
| from Model import MyModel | |||
| LEN_SEQ = 64 | |||
| PRED = 0.027 | |||
| HIDDEN = 128 | |||
| model = MyModel(HIDDEN) | |||
| dataset = np.load('dataset.npy') | |||
| scale = (np.max(dataset) - np.min(dataset)) | |||
| data = dataset/scale | |||
| shift = np.min(data) | |||
| data = data - shift | |||
| annee = np.array(list(range(len(data))))/365 | |||
| annee = annee - annee[-1] | |||
| start_pred = int(len(data)*(1-PRED)) | |||
| print(len(data)) | |||
| print(start_pred) | |||
| plt.figure(1) | |||
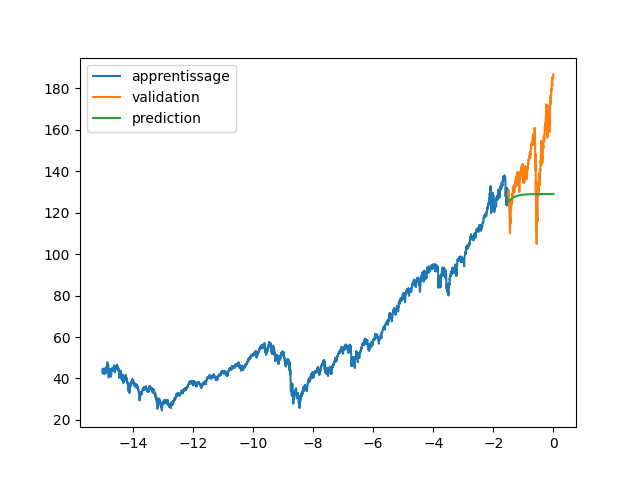
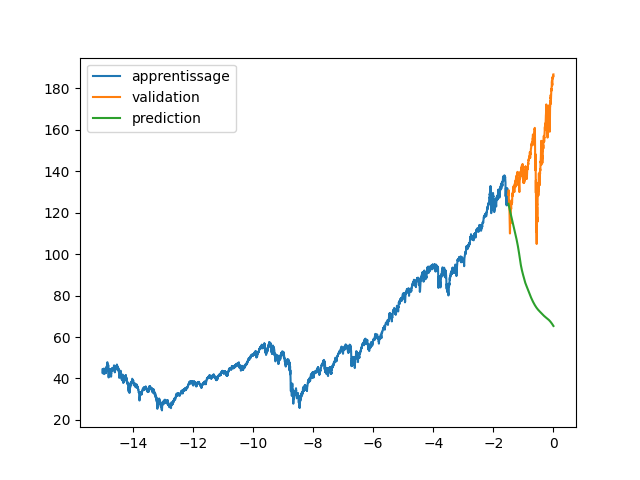
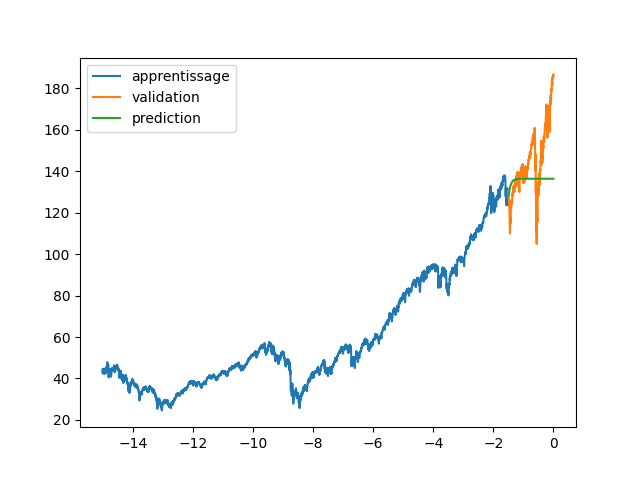
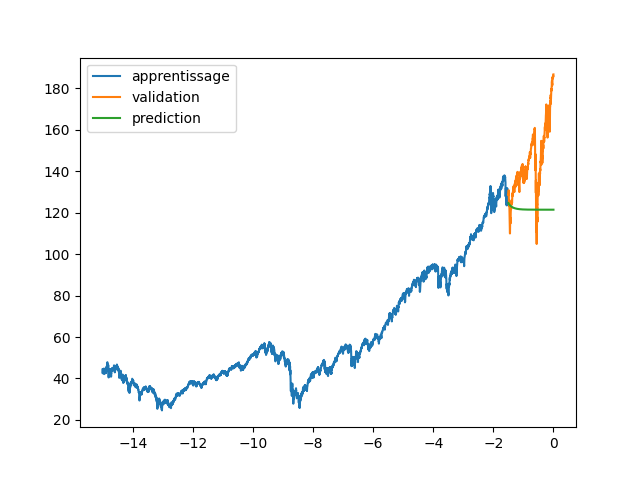
| plt.plot(annee[:start_pred],data[:start_pred], label="apprentissage") | |||
| plt.plot(annee[start_pred:],data[start_pred:], label="validation") | |||
| plt.legend() | |||
| plt.show() | |||
| X_train_tot = [data[0:start_pred-1]] | |||
| Y_train_tot = [data[1:start_pred]] | |||
| X_train_tot = np.expand_dims(np.array(X_train_tot),2) | |||
| Y_train_tot = np.expand_dims(np.array(Y_train_tot),2) | |||
| X_train = X_train_tot[:,:LEN_SEQ,:] | |||
| Y_train = Y_train_tot[:,:LEN_SEQ,:] | |||
| for i in range(len(X_train_tot[0]) - LEN_SEQ) : | |||
| X_train = np.concatenate((X_train, X_train_tot[:,i:i+LEN_SEQ,:]),0) | |||
| Y_train = np.concatenate((Y_train, Y_train_tot[:,i:i+LEN_SEQ,:]),0) | |||
| print(X_train_tot.shape) | |||
| print(X_train.shape) | |||
| model.compile(optimizer='adam', | |||
| loss='binary_crossentropy', | |||
| metrics=['binary_crossentropy']) | |||
| import os | |||
| os.system("rm -rf log_dir") | |||
| model.fit(x=X_train, y=Y_train, batch_size=16, epochs=5, shuffle=True) | |||
| Pred = X_train_tot.copy() | |||
| while len(Pred[0]) < len(data) : | |||
| print(len(data) - len(Pred[0])) | |||
| Pred = np.concatenate((Pred, np.array([[model.predict(Pred)[0][-1]]])),1) | |||
| Pred = Pred + shift | |||
| Pred = Pred * scale | |||
| data_Pred = np.squeeze(Pred) | |||
| plt.figure(2) | |||
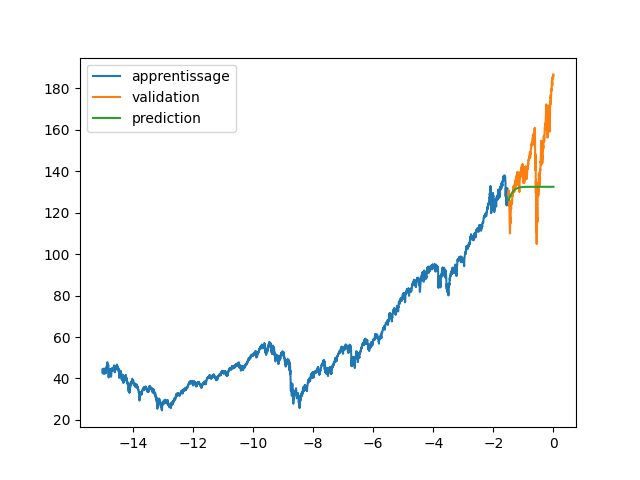
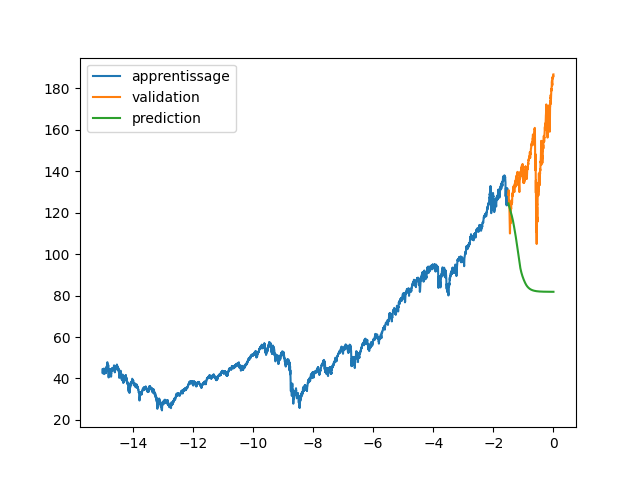
| plt.plot(annee[:start_pred],dataset[:start_pred], label="apprentissage") | |||
| plt.plot(annee[start_pred:],dataset[start_pred:], label="validation") | |||
| plt.plot(annee, data_Pred, label="prediction") | |||
| plt.legend() | |||
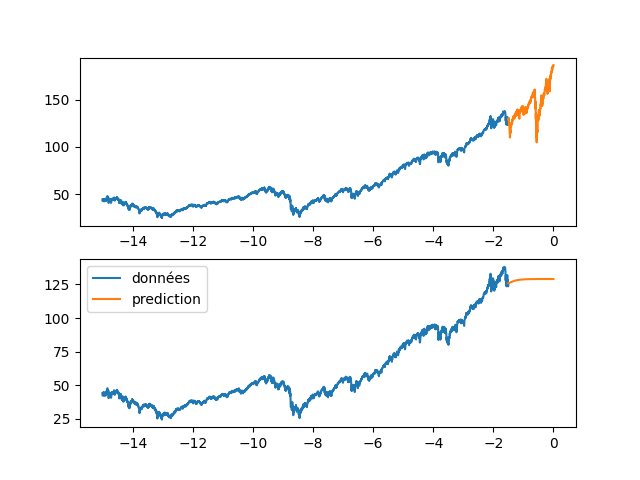
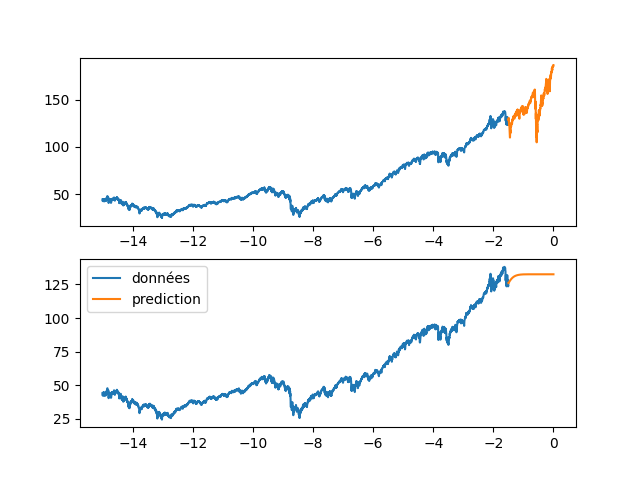
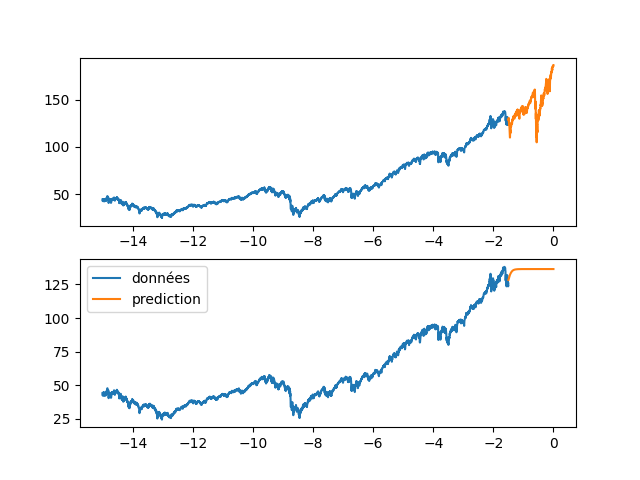
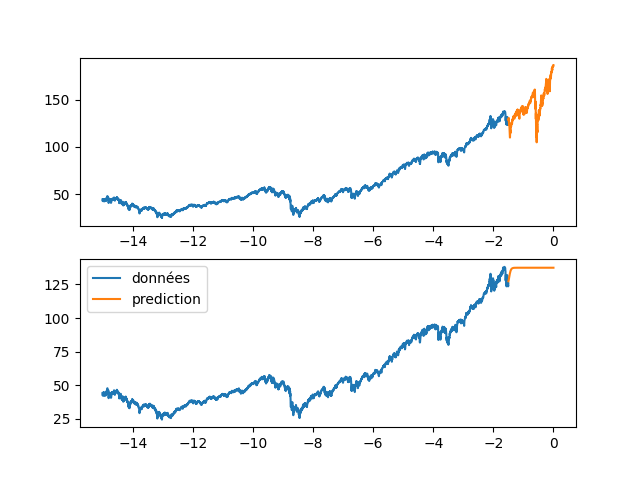
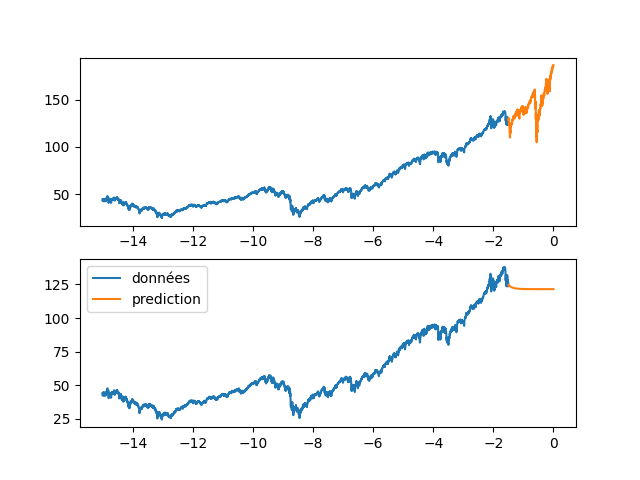
| fig, axs = plt.subplots(2) | |||
| axs[0].plot(annee[:start_pred],dataset[:start_pred], label="données") | |||
| axs[0].plot(annee[start_pred:],dataset[start_pred:], label="validation") | |||
| axs[1].plot(annee[:start_pred],dataset[:start_pred], label="données") | |||
| axs[1].plot(annee[start_pred:], data_Pred[start_pred:], label="prediction") | |||
| plt.legend() | |||
| plt.show() | |||
| import optuna | |||
| def objectif(trial) : | |||
| LEN_SEQ = trial.suggest_int('len_seq', 64,256) | |||
| PRED = 0.1 | |||
| HIDDEN = trial.suggest_int('hidden',32,256) | |||
| model = MyModel(HIDDEN) | |||
| dataset = np.load('dataset.npy') | |||
| scale = (np.max(dataset) - np.min(dataset)) | |||
| data = dataset/scale | |||
| shift = np.min(data) | |||
| data = data - shift | |||
| annee = np.array(list(range(len(data))))/365 | |||
| annee = annee - annee[-1] | |||
| start_pred = int(len(data)*(1-PRED)) | |||
| #print(len(data)) | |||
| #print(start_pred) | |||
| plt.figure(1) | |||
| plt.plot(annee[:start_pred],data[:start_pred], label="apprentissage") | |||
| plt.plot(annee[start_pred:],data[start_pred:], label="validation") | |||
| plt.legend() | |||
| #plt.show() | |||
| X_train_tot = [data[0:start_pred-1]] | |||
| Y_train_tot = [data[1:start_pred]] | |||
| X_train_tot = np.expand_dims(np.array(X_train_tot),2) | |||
| Y_train_tot = np.expand_dims(np.array(Y_train_tot),2) | |||
| X_train = X_train_tot[:,:LEN_SEQ,:] | |||
| Y_train = Y_train_tot[:,:LEN_SEQ,:] | |||
| for i in range(len(X_train_tot[0]) - LEN_SEQ) : | |||
| X_train = np.concatenate((X_train, X_train_tot[:,i:i+LEN_SEQ,:]),0) | |||
| Y_train = np.concatenate((Y_train, Y_train_tot[:,i:i+LEN_SEQ,:]),0) | |||
| #print(X_train_tot.shape) | |||
| #print(X_train.shape) | |||
| model.compile(optimizer='adam', | |||
| loss='binary_crossentropy', | |||
| metrics=['binary_crossentropy','mse']) | |||
| import os | |||
| os.system("rm -rf log_dir") | |||
| model.fit(x=X_train, y=Y_train, batch_size=16, epochs=5, shuffle=True) | |||
| Pred = X_train_tot.copy() | |||
| while len(Pred[0]) < len(data)+500 : | |||
| print(len(data) - len(Pred[0])) | |||
| Pred = np.concatenate((Pred, np.array([[model.predict(Pred)[0][-1]]])),1) | |||
| Pred = Pred + shift | |||
| Pred = Pred * scale | |||
| data_Pred = np.squeeze(Pred) | |||
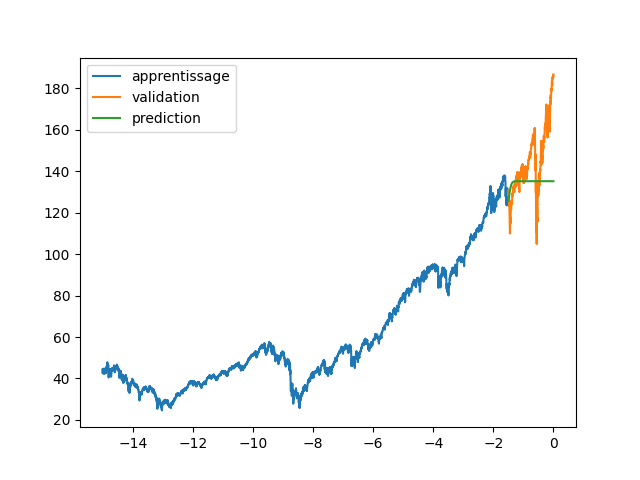
| plt.figure(2) | |||
| plt.clf() | |||
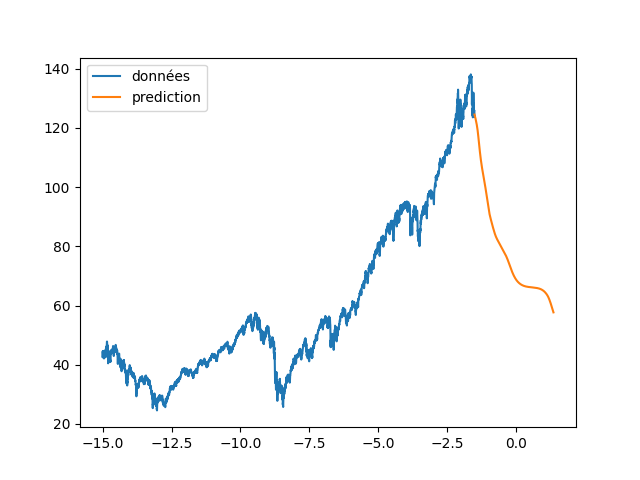
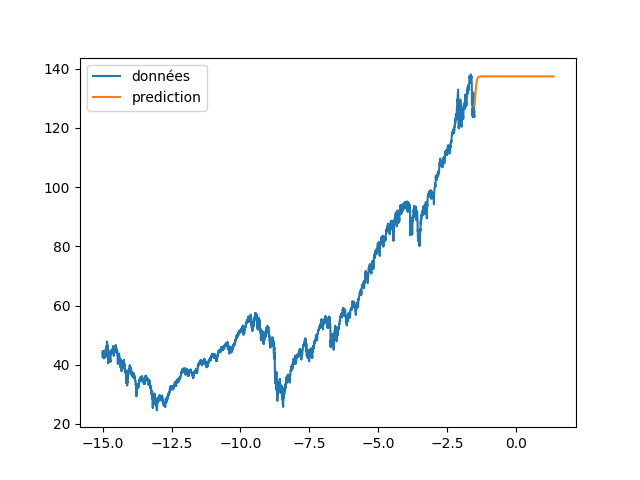
| plt.plot(annee[:start_pred],dataset[:start_pred], label="apprentissage") | |||
| plt.plot(annee[start_pred:],dataset[start_pred:], label="validation") | |||
| plt.plot(annee[start_pred:], data_Pred[start_pred:len(annee)], label="prediction") | |||
| plt.legend() | |||
| plt.savefig(f"images/{LEN_SEQ}_{HIDDEN}_fig2.png") | |||
| plt.figure(3) | |||
| plt.clf() | |||
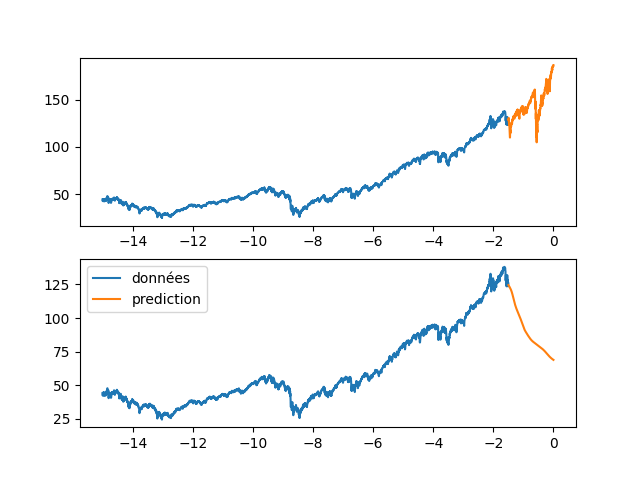
| fig, axs = plt.subplots(2) | |||
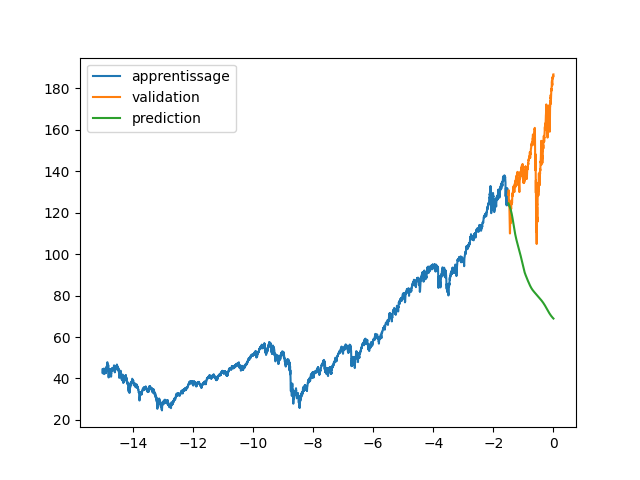
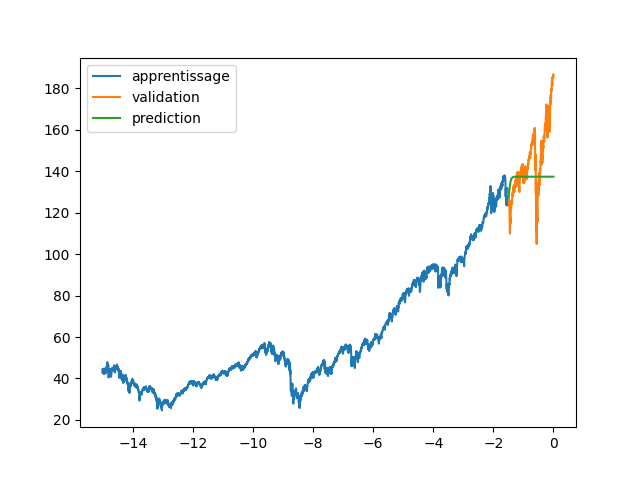
| axs[0].plot(annee[:start_pred],dataset[:start_pred], label="apprentissage") | |||
| axs[0].plot(annee[start_pred:],dataset[start_pred:], label="validation") | |||
| axs[1].plot(annee[:start_pred],dataset[:start_pred], label="données") | |||
| axs[1].plot(annee[start_pred:], data_Pred[start_pred:len(annee)], label="prediction") | |||
| plt.legend() | |||
| plt.savefig(f"images/{LEN_SEQ}_{HIDDEN}_fig3.png") | |||
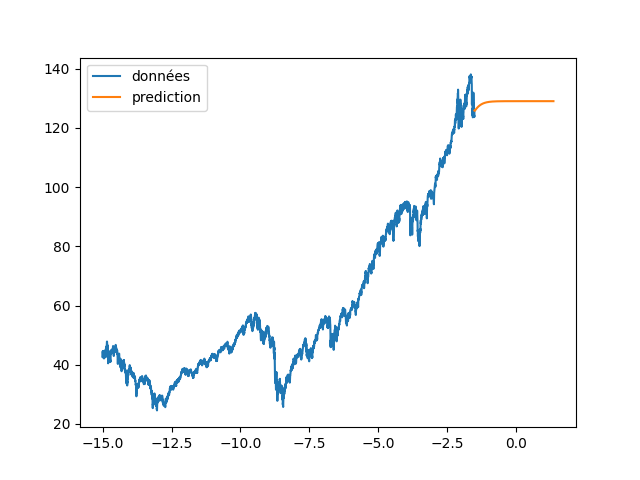
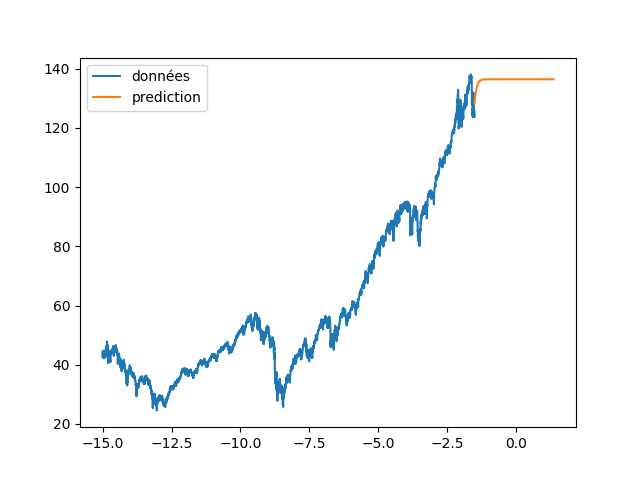
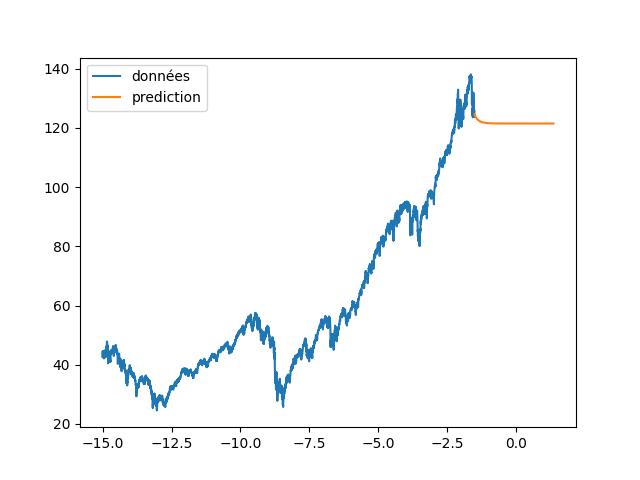
| annee_ex = np.array(list(range(len(data_Pred))))/365 | |||
| annee_ex = annee_ex + annee[0] | |||
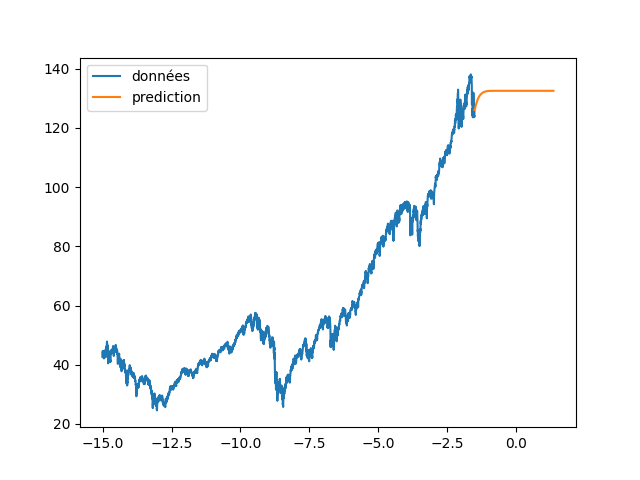
| plt.figure(4) | |||
| plt.clf() | |||
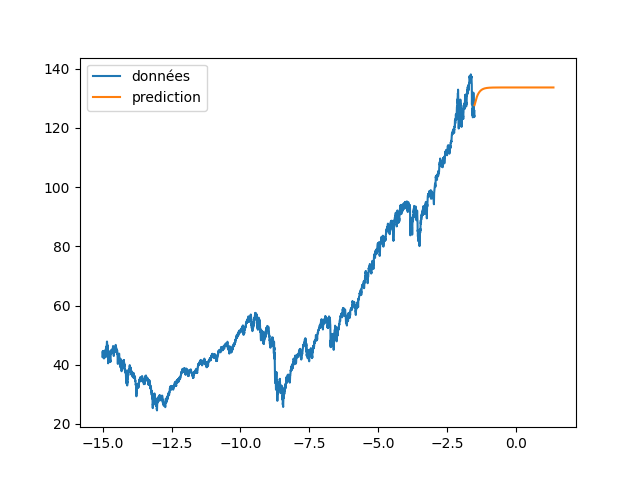
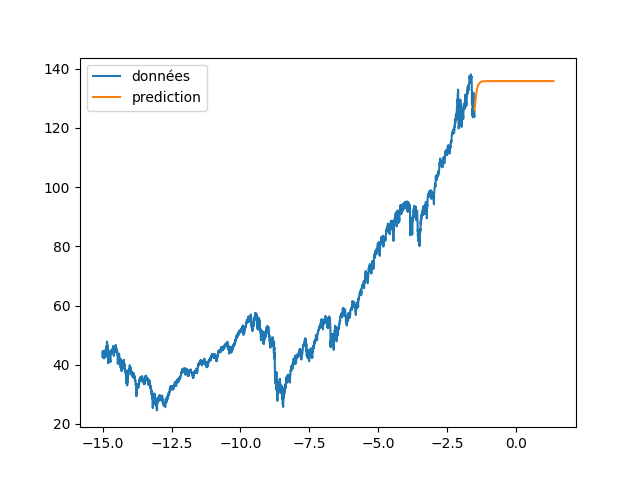
| plt.plot(annee[:start_pred],dataset[:start_pred], label="données") | |||
| plt.plot(annee_ex[start_pred:], data_Pred[start_pred:], label="prediction") | |||
| plt.legend() | |||
| plt.savefig(f"images/{LEN_SEQ}_{HIDDEN}_fig4.png") | |||
| loss = np.linalg.norm(dataset[start_pred:] - data_Pred[start_pred:len(dataset)])/(np.max(data_Pred[start_pred:]) - np.min(data_Pred[start_pred:])) | |||
| print(loss*100) | |||
| return loss | |||
| #plt.show() | |||
| study = optuna.create_study() | |||
| study.optimize(objectif, n_trials=10) | |||
Ładowanie…